

티스토리 뷰
SQL 코드카타
Q130. Select By ID
1. 문제 링크: https://www.hackerrank.com/challenges/select-by-id/problem
2. 정답 코드:
SELECT *
FROM CITY
WHERE ID = "1661";
Q131. Japanese Cities' Attributes
1. 문제 링크: https://www.hackerrank.com/challenges/japanese-cities-attributes/problem
2. 정답 코드:
SELECT *
FROM CITY
WHERE COUNTRYCODE = "JPN";
Q132. Japanese Cities' Names
1. 문제 링크: https://www.hackerrank.com/challenges/japanese-cities-name/problem
2. 정답 코드:
SELECT NAME
FROM CITY
WHERE COUNTRYCODE = "JPN";
Q113. 1978. Employees Whose Manager Left the Company
1. 문제 링크: https://leetcode.com/problems/employees-whose-manager-left-the-company/description/
2. 정답 코드:
SELECT employee_id
FROM Employees
WHERE salary < 30000
AND manager_id NOT IN (
SELECT employee_id
FROM Employees
)
ORDER BY employee_id;3. 오류 상황: 테스트는 제대로 구현했지만, 다른 케이스에서는 값이 나오지 않음
4. 시도 방법: 어떤 부분에서 잘못된 건지
5. 최종 문제 해결 방법: manager_id IS NOT NULL이라는 조건에서 필요한 행까지 필터링되어 해당 조건을 삭제함
근데 아무리 생각해도 이해가 잘 안 가서 생성형 AI에게 물어봤다!
생성형 AI 답변)
IN이나 NOT IN 뒤에 들어가는 서브쿼리는 "내가 비교할 대상이 담긴 바구니"라고 생각하면 쉽다!
작성했던 쿼리가 왜 논리적으로 꼬였는지, 그림과 예시로 아주 쉽게 설명해 보자.
1. 잘못된 바구니 (작성한 쿼리)
나는 서브쿼리(NOT IN 괄호 안)에 조건을 이렇게 걸었는데,
SELECT employee_id
FROM Employees
WHERE manager_id IS NOT NULL이건 "상사가 있는 직원의 ID 목록"을 가져오라는 뜻이다
- 직원 A (ID : 1, 상사 : 없음)
- 직원 B (ID : 2, 상사 : 1번)
- 이 상황에서 위 서브쿼리를 실행하면 ID 2번만 바구니에 담긴다 (1번은 상사가 없어서 탈락!)
- 그럼 메인 쿼리는 "상사 ID가 2번이 아닌 사람"을 찾게 되는데, 정작 확인해야 할 1번(사장님)이 바구니에 없어서 비교를 못 하게 된다
2. 올바른 바구니 (정답 로직)
내가 확인하고 싶은 건 "이 상사 번호가 우리 회사 직원 명단에 있는 번호인가?"이므로, 바구니에는 조건 없이 모든 직원의 ID가 다 들어있어야 한다
SELECT employee_id
FROM Employees이 바구니에는 1번(사장님), 2번(직원)이 다 들어있을 것이다! 이제 내 상사 번호가 이 바구니에 없으면 "명단에 없는 상사"라고 확신 가능!
SELECT employee_id
FROM Employees
WHERE salary < 30000
AND manager_id NOT IN (
SELECT employee_id
FROM Employees
WHERE manager_id IS NOT NULL
)
ORDER BY employee_id;# 이전에 작성했던 쿼리
Q122. 196. Delete Duplicate Emails
1. 문제 링크: https://leetcode.com/problems/delete-duplicate-emails/description/
2. 정답 코드:
DELETE p1
FROM Person as p1, person as p2
WHERE p1.email = p2.email
AND p1.id > p2.id;3. 오류 상황: SELECT가 아닌 DELETE는 처음 봄
4. 시도 방법: 사용법을 알기 위해 생성형 AI에게 물어봄
5. 최종 문제 해결 방법: DELETE 사용 + 셀프 JOIN (JOIN 조건 따로 없이 FROM에 테이블 2번 써주기) 해서 문제 풀이
헷갈리는 개념 이해하기) 중복 이메일 삭제하기 : Self Join과 DELETE의 원리
SQL 문제를 풀다 보면 "중복된 데이터 중 하나만 남기고 나머지는 삭제하라"는 요구사항을 자주 만나게 된다
특히 SELECT가 아닌 DELETE 문에서 자기 자신의 테이블을 참조하는 방식은 초보자에게 매우 생소할 수 있다
셀프 조인(Self Join)의 매칭 원리를 통해 이 문제를 완벽히 파헤쳐 보겠다!
1. 문제 상황
- Person 테이블에 이메일이 중복되어 저장되어 있음
- 이메일당 ID가 가장 작은 데이터 하나만 남기고 나머지는 모두 삭제해야 함
2. 핵심 개념 : 셀프 조인(Self Join)이란?
셀프 조인은 별도의 테이블이 있는 게 아니라, 나와 똑같은 테이블 복사본을 하나 더 만들어서 나란히 두고 비교하는 것
이때 컴퓨터는 우리가 명령한 조건에 맞는 데이터를 찾기 위해 내부적으로 두 테이블의 모든 행을 무작위로 한 번씩 다 짝지어 본다! (지난번에도 언급했던 '카테시안 곱')
3. 해결 로직 : "너, 나보다 번호가 크네?"
작성해야 하는 쿼리의 핵심 논리는 아래와 같다
"나(p1)랑 이메일이 똑같은 사람(p2)을 전부 데려와봐. 그중에서 나보다 ID가 작은 사람이 단 한 명이라도 있다면, 나는 중복 데이 터니까 삭제될게!"
쿼리 작성 (MySQL 기준)
DELETE p1
FROM Person p1, Person p2
WHERE p1.email = p2.email
AND p1.id > p2.id;
4. 무작위 매칭 과정 시뮬레이션
컴퓨터가 p1과 p2를 어떻게 매칭하고 필터링하는지 표로 살펴보자
(예: ID 1번과 3번이 john@example.com으로 중복인 상황)
| 매칭 조합 (p1 - p2) | 이메일 일치? | p1.id > p2.id ? | 결과 (DELETE p1) |
| (ID:1) - (ID:1) | YES | NO (1 > 1 아님) | 생존 |
| (ID:1) - (ID:3) | YES | NO (1 > 3 아님) | 생존 |
| (ID:3) - (ID:1) | YES | YES (3 > 1) | 삭제 확정! |
| (ID:3) - (ID:3) | YES | NO (3 > 3 아님) | 생존 |
| (ID:1) - (ID:2) | NO (이메일 다름) | - | 생존 |
결론:
ID 3번은 자기보다 ID가 작은 1번과 매칭되었을 때, "이메일은 같고 내 번호가 더 크다"는 조건이 충족된다
따라서 DELETE p1 명령에 의해 3번 행은 삭제되고, 반면 1번은 자기보다 작은 번호를 가진 동일 이메일 소유자를 절대 찾을 수 없기 때문에 끝까지 살아남는다!
5. 주의할 점 및 요약
- DELETE 대상 명시 : DELETE p1처럼 어떤 별칭(Alias)의 데이터를 지울지 명확히 써줘야 함
- 비교 연산자 : p1.id > p2.id는 가장 작은 것을 남기겠다는 뜻이고, 반대로 가장 큰 ID를 남기고 싶다면 <를 사용하면 된다
- 성능 : 데이터가 수백만 건이라면 모든 조합을 비교하는 방식이 느릴 수 있지만, 입문 단계에서 로직을 이해하기에는 가장 완벽한 방법!

Python 코드카타 (https://github.com/heeso0908/codekata.git)
Q41. 이상한 문자 만들기
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/12930
2. 정답 코드:
def solution(s):
split_s = s.split(" ")
new_s = []
for i in range(len(split_s)) :
for j in range(len(split_s[i])) :
if j % 2 == 0 :
new_s.append(split_s[i][j].upper())
else :
new_s.append(split_s[i][j].lower())
if i < len(split_s) -1 :
new_s.append(" ")
return "".join(new_s)크게 2개의 리스트가 중첩되어 있다고 생각하면 편하다!
문자열 s가 "try hello world" 라면, [["t", "r", "y"], ["h", "e", "l", "l", "o"], ["w", "o", "r", "l", "d"]] 이렇게 쪼개서 생각!
내부 리스트에서 짝수번째 글자는 대문자, 홀수번째 글자는 소문자로 바꿔준다!
그리고 중간에 공백을 넣을 때는 맨 마지막에는 들어가면 안되니까 if 문을 활용해서 len(split_s) - 1 보다 외부 리스트의 인덱스가 작을 때만 공백을 넣어야 한다
마지막으로 모두 join 해주면 되는데, 이때는 그대로 붙이면 되니까 sorted는 안 적어도 된다!
Q42. 삼총사
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/131705
2. 정답 코드:
def solution(number):
result = 0
for i in range(len(number)) :
for j in range(i+1, len(number)) :
for k in range(j+1, len(number)) :
if number[i] + number[j] + number[k] == 0 :
result += 1
return result3개의 숫자를 더해서 0이 나와야 하므로 for 문을 3번 사용해서 range(len(number)) 기준으로 숫자 조합을 찾으면 되는데,
이때 주의할 점은 i < j < k 여야 조합을 이루는 숫자가 중복이 되지 않고 조합 개수를 확실하게 찾을 수 있다!
예를 들어서, [-1, -2, 3, 8, 10] 이렇게 number가 주어졌는데 더했을 때 0이 되는 3가지 숫자 조합이
[-1, -2, 3] 도 되고, [-1, 3, -2] 도 되고, [-2, -1, 3] 도 되고, [-2, 3, -1], ... 이런 식으로 중복해서 나올 수도 있기 때문이다!
그래서 i는 0부터, j는 i+1 부터, k는 j+1 부터로 인덱스를 설정해 주면 중복 케이스가 제거된다.
def solution(number):
result = 0
for i in range(len(number)) :
for j in range(len(number)) :
for k in range(len(number)) :
if number[i] + number[j] + number[k] == 0 :
result += 1
return result# 이전에 작성한 코드 - 개수가 중복으로 계산됨
Q43. 크기가 작은 부분문자열
1. 문제 링크: http://school.programmers.co.kr/learn/courses/30/lessons/147355
2. 정답 코드:
def solution(t, p):
answer = 0
for i in range(0, len(t)-len(p)+1) :
num = ""
for j in range(i, i+len(p)) :
num += t[j]
if num <= p :
answer += 1
return answer3. 오류 상황: 코드는 돌아가는데 answer 정답이 다름
4. 시도 방법: 해결할 방법을 모르겠어서 생성형 AI에게 물어봄
5. 최종 문제 해결 방법:
- num = "" 의 위치 : num은 외부 루프가 한 번 돌 때마다(새로운 숫자를 만들 때마다) 비워져야 함. 현재는 for문 밖(맨 처음)에 있어서 숫자가 계속 쌓이게 된다
- if num <= p 비교 : num[i]라고 쓰면 전체 문자열이 아니라 특정 글자 하나만 가리키게 된다. 잘라낸 덩어리 전체(num)를 p와 비교해야 함
부분 문자열을 만들 때는 문자열 p의 길이만큼 잘라야 하므로,
첫 번째 for문의 범위를 range(0, len(t)-len(p)+1)로 설정하여 비교가 필요한 모든 시작점을 포함해 준다
ex) t가 "3141592"(7자리)이고 p가 "271"(3자리)라면, range(0, 7-3+1)
→ 즉 range(0, 5)가 되어 인덱스 0~4까지 다섯 번 탐색
두 번째 for문에서는 추출할 부분 문자열의 구간을 정한다
만약 i = 0이라면 t[0:3]에 해당하는 글자들을 모아야 하므로, 범위를 range(i, i+len(p))로 설정하여 p의 길이만큼 정확히 글자를 이어 붙인다!
마지막으로, 이렇게 완성된 부분 문자열(num)과 p 크기를 비교하는 if문을 실행한다
조건(num <= p)을 만족할 때마다 answer를 1씩 증가시켜 최종적인 개수를 구한다!
def solution(t, p):
answer = 0
num = ""
for i in range(0, len(t)-len(p)+1) :
for j in range(i, i+len(p)) :
num += t[j]
if num[i] <= p :
answer += 1
return answer# 이전에 작성한 코드
미니 세션) 파이썬 전처리
Parquet?
빅데이터를 빠르고 효율적으로 처리하기 위해 고안된 저장 방식 → CSV 여러 개 봐야 할 때 유용!
1. CSV vs Parquet: 저장 방식의 차이
- CSV (행 기반) : 이름, 나이, 직업이 한 줄씩 묶여서 저장됩니다. 특정 사람의 정보를 통째로 읽을 때 유리
- Parquet (열 기반) : '이름' 데이터끼리 모으고, '나이' 데이터끼리 따로 모아서 저장! 수만 명의 데이터 중 '평균 나이'만 계산하고 싶을 때, 나이 열만 쏙 골라 읽을 수 있어 압도적으로 빠름
2. 왜 Parquet를 쓸까? (주요 장점)
- 압축률이 매우 높음 : 같은 열에는 비슷한 데이터(예: 같은 직업, 비슷한 나이대)가 모여 있어 압축 효율이 굉장히 좋아서 CSV에 비해 용량을 75% 이상 줄일 수 있음
- 비용 절감 (클라우드 최적화) : AWS나 Google Cloud 같은 환경에서는 '데이터를 읽은 양'만큼 돈을 내는데, Parquet은 필요한 열만 읽기 때문에 불필요한 데이터를 스캔하지 않아 돈이 훨씬 적게 듦
- 데이터 스키마 포함 : 파일 자체에 데이터 구조(타입, 이름 등) 정보가 들어있어서 CSV처럼 "이 숫자가 정수인가, 실수인가?"를 고민할 필요가 없음
3. 언제 쓰면 좋을까?
- 빅데이터 분석 : 수억 건의 데이터 중 특정 항목만 골라 통계를 낼 때
- 데이터 웨어하우스 : 하둡(Hadoop), 스파크(Spark), AWS Athena 등을 사용할 때 표준처럼 쓰임
- 단점 : 데이터를 한 줄씩 실시간으로 추가(Insert)하거나 수정하는 작업에는 부적합(이럴 땐 일반 DB 형식이 낫다)
loc와 iloc
- loc : 라벨 기반으로 값을 가져옴
- iloc : i(int) 값을 기반으로 값을 가져옴
라벨 == 인덱스 안에 들어 있는 값(이름표)
loc → 라벨로 찾기
인덱스 == 행을 구분하기 위한 구조
iloc → 순서로 찾기
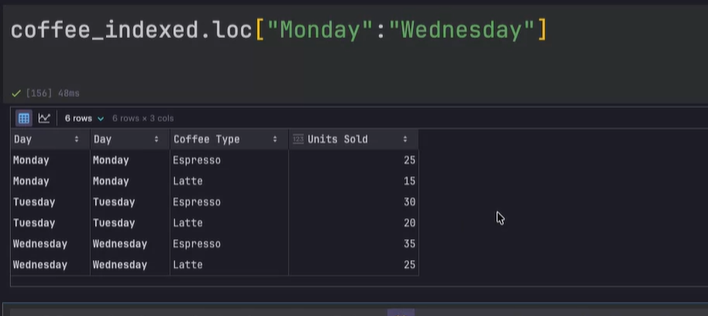
loc 문법
df.loc[행_선택, 열_선택]
행_선택 == 행(라벨) 중에서 True 만 선택할 거야! (==조건)


AND, OR 조건
pandas에서는 AND, OR 말고 &, | 사용해야 함
조건은 무조건 (괄호) 해주기 -> 가독성 증가!
(조건 1) & (조건 2)
(조건 1) | (조건 2)
라이브 세션) 데이터 전처리/시각화 5일차 - [시각화]
타깃 변환
# 3) 타겟 변환: no_show (Yes=1, No=0)
df2["no_show"] = df2["no_show"].map({"Yes": 1, "No": 0})
연령대별 그룹화
bins = [-1, 0, 12, 18, 30, 45, 60, 75, 110]
labels = ["0", "1-12", "13-18", "19-30", "31-45", "46-60", "61-75", "76+"]
df2["age_group"] = pd.cut(df2["age"], bins=bins, labels=labels)
내일 성취도 평가 대비를 위해 파이썬 기초 복습을 진행하려 했지만, 세션들이 생각보다 길어지면서 개인 공부를 거의 하지 못했다 ㅠㅡㅠ
오늘 라이브 세션에서는 이전보다 훨씬 많은 양의 데이터를 가지고 전처리와 시각화를 진행했고, 추가로 머신러닝이 어떻게 이루어지는 지에 대해서도 잠깐 맛볼 수 있었다.
‘데이터 분석이란 이런 것이구나’라는 생각이 들면서도, 한편으로는 정말 갈 길이 멀다는 걱정이 동시에 들었다.
내일부터는 기초 프로젝트 주차가 시작된다. 그동안 배웠던 내용을 실제로 적용해 결과를 도출해야 한다는 점에서 막막함도 있지만, 한편으로는 직접 해볼 수 있다는 점에서 기대도 된다.
컨디션 조절을 잘해서 이번 주 마지막 날까지 잘 마무리해야겠다!
'내일배움캠프 데이터 분석' 카테고리의 다른 글
| 24일차) 내일배움캠프 데이터 분석 TIL - 기초 프로젝트(2) (0) | 2026.01.26 |
|---|---|
| 23일차) 내일배움캠프 데이터 분석 TIL - 기초 프로젝트(1) (0) | 2026.01.23 |
| 21일차) 내일배움캠프 데이터 분석 TIL - 파이썬 전처리/시각화(4) (0) | 2026.01.21 |
| 20일차) 내일배움캠프 데이터 분석 TIL - 파이썬 전처리/시각화(3) (0) | 2026.01.20 |
| 19일차) 내일배움캠프 데이터 분석 TIL - 파이썬 전처리/시각화(2) (2) | 2026.01.19 |
- Total
- Today
- Yesterday
- 판다스
- github
- 파이썬입문
- 코드카타
- 데이터분석입문
- 구글코랩
- Til
- 데이터분석
- Tableau
- 머신러닝
- 비전공자코딩
- 텍스트분석
- 코딩처음
- 코딩기초
- 내일배움캠프
- 데이터시각화
- GoogleColab
- Python
- 프로그래밍입문
- 중학생코딩
- git
- 통계
- 파이썬
- 태블로
- SQL
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |