

티스토리 뷰
SQL 코드카타
Q99. 2356. Number of Unique Subjects Taught by Each Teacher
1. 문제 링크: https://leetcode.com/problems/number-of-unique-subjects-taught-by-each-teacher/description/
2. 정답 코드:
SELECT
teacher_id,
COUNT(DISTINCT subject_id) as cnt
FROM Teacher
GROUP BY teacher_id;
Q100. 1141. User Activity for the Past 30 Days I
1. 문제 링크: https://leetcode.com/problems/user-activity-for-the-past-30-days-i/
2. 정답 코드:
SELECT
activity_date as day,
COUNT(DISTINCT user_id) as active_users
FROM Activity
WHERE activity_date >= '2019-06-28' AND activity_date <= '2019-07-27'
GROUP BY activity_date;
Q102. 596. Classes With at Least 5 Students
1. 문제 링크: https://leetcode.com/problems/classes-with-at-least-5-students/description/
2. 정답 코드:
SELECT class
FROM Courses
GROUP BY class
HAVING COUNT(student) >= 5;
Q103. 1729. Find Followers Count
1. 문제 링크: https://leetcode.com/problems/find-followers-count/description/
2. 정답 코드:
SELECT
user_id,
COUNT(*) as followers_count
FROM Followers
GROUP BY user_id
ORDER BY user_id;
Q104. 619. Biggest Single Number
1. 문제 링크: https://leetcode.com/problems/biggest-single-number/
2. 정답 코드:
SELECT MAX(num) as num
FROM(SELECT num
FROM MyNumbers
GROUP BY num
HAVING COUNT(num) = 1
) as result;3. 오류 상황: 중복되지 않은 단일 값이 없을 때 NULL 표시를 해야 하는데, CASE WHEN 문이나 IF 문을 사용해도 NULL 출력 안됨
4. 시도 방법: NULL로 표현하기 위한 방법에는 어떤 것이 있는지 생성형 AI에게 힌트를 물어봄
5. 최종 문제 해결 방법: 서브쿼리를 사용해서 단일 값만을 찾아주고 이를 MAX로 가장 큰 숫자를 찾는데, MAX 같은 집계 함수 자체가 값이 들어오지 않으면 NULL 처리를 해준다!

생성형 AI 설명) 전교에서 단 한 명만 받은 점수 중 가장 높은 점수 찾기와 같다!
[1단계] 서브 쿼리: "혼자 온 사람 손 들어!"
전체 숫자 카드 뭉치(MyNumbers)에서 중복되지 않은 숫자만 골라내는 과정
- GROUP BY num : 같은 숫자가 적힌 카드끼리 모둠을 만든다 (예: 1번 모둠, 2번 모둠...)
- HAVING COUNT(num) = 1 : 모둠원을 세어보고, 딱 1명만 있는 모둠만 남긴다. 2명 이상(중복)인 숫자는 여기서 탈락!
- as result : 이 결과물(후보 리스트)에 '결과'라는 이름표를 붙이기
[2단계] 메인 쿼리 : "그중 제일 큰 놈, 혹은 빈 상자"
이제 후보들 중에서 MAX() 함수로 제일 큰 값을 찾을 차례!
- 가장 큰 값 찾기 : 후보들 중에서 수학의 최댓값(MAX)을 구하듯 가장 큰 숫자를 딱 하나 뽑는다
- NULL 처리 : 만약 1단계에서 후보가 한 명도 안 나왔다면? 그냥 SELECT num만 하면 화면에 아무것도 안 뜨고 끝남 → MAX(num)은 "후보가 없네? 그럼 '비어있음'이라는 뜻으로 NULL을 출력할게"라고 친절하게 빈 상자(NULL)를 하나 만들어서 보여준다!
왜 ORDER BY와 LIMIT은 안 써도 될까?
수학 시험에서 "반에서 점수가 가장 높은 학생 한 명의 점수를 써라"라고 하면, 이미 최댓값(MAX)을 구하는 순간 답은 하나로 결정!
따라서 굳이 점수 순서대로 줄을 세우거나(ORDER BY), 한 명만 뽑으라고(LIMIT 1) 다시 말할 필요가 없다. MAX() 함수가 그 일을 이미 다 해줬으니까!
Python 코드카타 (https://github.com/heeso0908/codekata.git)
Q26. 음양 더하기
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/76501
2. 정답 코드:
def solution(absolutes, signs):
answer = 0
for i in range(len(absolutes)) :
if signs[i] :
answer += absolutes[i]
else :
answer -= absolutes[i]
return answer3. 오류 상황: 계속 음수 적용이 안됨
4. 시도 방법: 왜 False 조건일 때 빼기를 하지 않는지 생성형 AI에게 힌트를 물어봄
5. 최종 문제 해결 방법: if signs : 라고 하면 파이썬에서는 값이 들어있는 리스트는 항상 True로 생각해서 else 구문으로 넘어가지 않기 때문에 빼기가 되지 않았다! 그래서 인덱스 값을 사용하는 for 문+if 문으로 변경해야 한다.
for i in absolutes: 루프 안에서 i는 숫자 값일 뿐, 현재 몇 번째 숫자인지에 대한 정보가 없다.
그래서 signs의 몇 번째 부호를 써야 할지 알 수 없었던 것!
def solution(absolutes, signs):
answer = 0
for i in absolutes :
if signs :
answer += i
else :
answer -= i
return answer# 이전에 작성한 코드
추가로, 리스트의 인덱스와 값을 한번에 가져올 수 있는 ZIP 함수를 사용해서 더 간단하게 코드를 작성할 수 있다!
def solution(absolutes, signs):
answer = 0
# num(숫자)과 sign(부호)을 동시에 하나씩 꺼내옵니다.
for num, sign in zip(absolutes, signs):
if sign:
answer += num
else:
answer -= num
return answer
Q27. 핸드폰 번호 가리기
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/12948
2. 정답 코드:
def solution(phone_number):
answer = (len(phone_number)-4)*'*' + phone_number[-4:]
return answer
Q28. 없는 숫자 더하기
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/86051
2. 정답 코드:
def solution(numbers):
answer = 0
for i in range(10) :
if i in numbers :
answer += 0
else :
answer += i
return answer
Q29. 제일 작은 수 제거하기
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/12935
2. 정답 코드:
def solution(arr):
answer = []
min_num = min(arr)
if len(arr) <= 1 :
return [-1]
for i in arr :
if i != min_num :
answer.append(i)
return answer3. 오류 상황: 한가지 케이스만 시간 초과로 오류가 뜸
4. 시도 방법: 해결할 방법을 모르겠어서 생성형 AI에게 물어봄
5. 최종 문제 해결 방법: for 문 안에서 min(arr)를 사용하면 계산 시간이 오래 걸려서 시간 초과로 오답 처리가 되므로, 처음에 min(arr) 값을 먼저 구해 다른 변수로 저장해준다!
코드카타를 풀면서 계산 시간이 오래 걸려 오답 처리된 경험은 이번이 처음이었다.
다양한 케이스를 고려해야 하는 문제를 접하다 보니, 문제 풀이 과정에서 신경 써야 할 요소가 생각보다 훨씬 많다는 것을 다시 한 번 느꼈다.
또 내가 미처 생각하지 못한 예외 상황이 존재할 수 있다는 점에서, 앞으로는 수도 코드를 작성할 때부터 가능한 경우의 수를 충분히 고려하며 접근해야겠다는 생각이 들었다.
def solution(arr):
answer = []
for i in range(len(arr)) :
if arr[i] - min(arr) != 0 :
answer.append(arr[i])
if len(arr) == 1 :
answer.append(-1)
return answer# 맨 처음 작성했던 코드
Q20. 가운데 글자 가져오기
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/12903
2. 정답 코드:
def solution(s):
answer = ''
if len(s) % 2 == 0 :
answer = s[len(s)//2-1:len(s)//2+1]
else :
answer = s[len(s)//2]
return answer3. 오류 상황: 리스트 슬라이싱할 때는 정수가 들어가야 한다는 오류 메시지가 뜸
4. 시도 방법: 짝수일 때는 정수가 들어갈텐데 계속 오류가 나서 생성형 AI에게 물어봄
5. 최종 문제 해결 방법: 단순히 / 하는 것은 4/2를 해도 2.0 이런 식으로 float 형이기 때문에 정수로 구하기 위해 몫만 나오는 //를 사용해야 한다!
라이브 세션) 데이터 전처리/시각화 2일차 - [결측·중복·문자열 지옥 탈출: Pandas 클리닝 핵심]

→ 여기에서 top은 최빈값을 의미하고, freq는 최빈값이 몇번 나오는지를 의미!
- .loc = 라벨(이름) 기반 (행/열 이름으로 접근) (라벨 = feature = 속성)
- .iloc = 위치(순서) 기반 (0번째, 1번째…로 접근) → i는 index

조건 작성
- AND : &
- OR : |
- NOT : ~
SQL에서의 DISTINCT와 유사한 기능 → value_counts()
ex) df2["paid"].value_counts()
불리언 인덱싱 : 조건을 만족하는 행 값은 True로 표시, 아니라면 False

.loc[조건, [출력하고 싶은 컬럼들]]
정렬 = SQL의 ORDER BY
- sort_values = 값 기준 정렬
- sort_index = 인덱스 기준 정렬
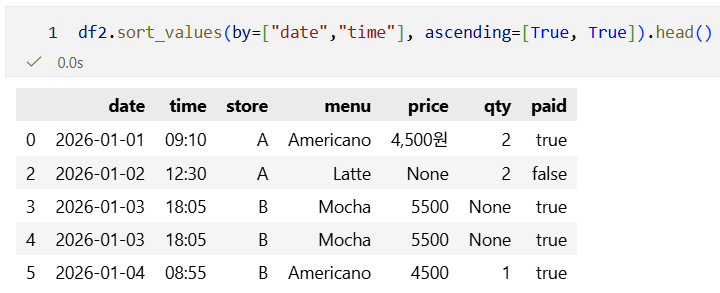
클리닝 기본기
1) rename / drop: 컬럼명 정리(선택)
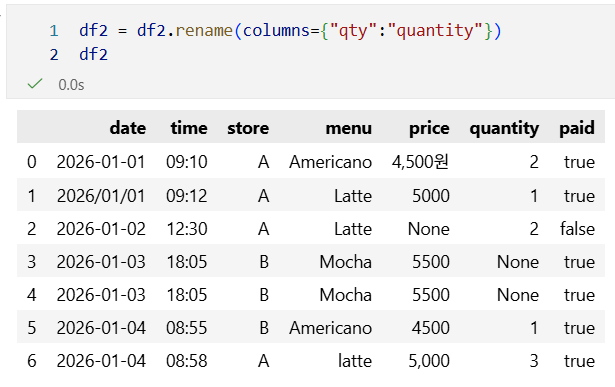
2) 문자열 정리: menu 공백/대소문자 통일

참고로 여기서 .title()은 앞 글자만 대문자로 바꿔주는 메서드
3) price 정리: “원”, “,” 제거하고 숫자로 만들기


4) 결측치 처리: dropna vs fillna (전략 선택)
- 삭제(drop): 데이터가 적어도 괜찮고, 결측이 중요 변수면 제거
- 대체(fill): 평균/중앙값/메뉴별 평균 등으로 대체

중복 처리: duplicated() / drop_duplicates()
duplicated() 메서드 사용하면 True, False 값으로 나옴
clean = clean.drop_duplicates(keep="first") → 중복 값 중에서 첫번째 값만 남기고 drop out(삭제)해라
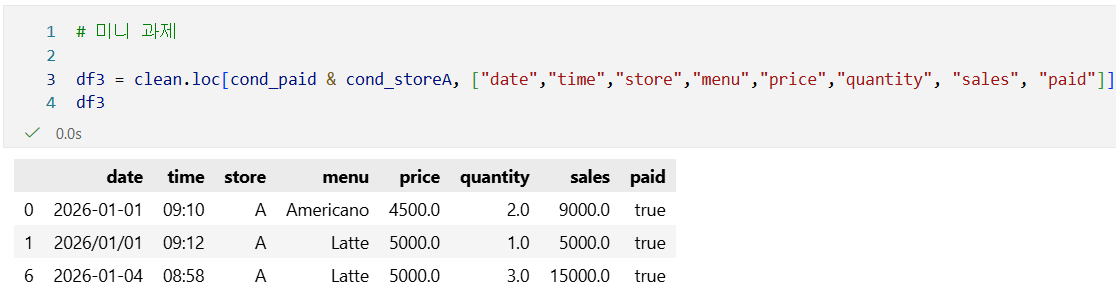
미니 과제
아래 조건을 만족하는 테이블 캡처(또는 출력)
- 결제 완료(true)
- store == "A"
- menu는 공백/대소문자 정리 완료
- sales 컬럼 포함
to_numeric(errors="coerce")로 결측 생기는 이유
to_numeric은 "이 리스트(또는 열)에 있는 값들을 숫자로 바꿔줘"라는 뜻
errors="coerce"는 "숫자로 못 바꾸는 걸 만나도 화내지 말고 그냥 '결측치(NaN)'로 표시해줘"라는 옵션
| 데이터 | to_numeric 결과 | 이유 |
| "1" | 1 | 숫자니까 성공! |
| "2.5" | 2.5 | 소수점 숫자니까 성공! |
| "모름" | NaN (결측치) | 숫자가 아니니까 NaN |
| "3층" | NaN (결측치) | '층'이라는 글자 때문에 NaN |
결측치 개수 세기 ★매우 중요★
df.isna().sum()
isna는 결측치라면 True를 반환, 값이 있으면 False
→ 결측치 갯수를 세려면 isna() 값을 sum!
df.dropna(inplace=True)
dropna() : "비어있는 줄은 버린다"
여기서 NA는 "Not Available"의 약자로, 데이터가 들어있지 않은 빈칸(결측치)을 의미
dropna는 이 빈칸이 하나라도 포함된 가로줄(행)을 찾아서 삭제하는 역할을 한다.
- 실행 전 : 이름은 있는데 점수가 비어있는 줄이 섞여 있는 상태
- 실행 후 : 점수가 없는 줄은 사라지고, 모든 칸이 채워진 줄만 남음
inplace=True : "복사본 말고 원본을 바로 고친다"
이 부분이 가장 중요합니다. 파이썬에서 많은 함수는 원본을 보호하기 위해 '결과물'만 따로 보여주려 합니다.
- inplace=True가 없을 때 : "빈칸을 지우면 이런 모양이 돼!"라고 화면에 보여주기만 할 뿐, 실제 데이터(df)는 변하지 않음 (임시로 확인만 할 때 사용)
- inplace=True를 썼을 때 : "보여줄 필요 없고, 지금 내가 가진 표(df)에서 바로 지워버려!"라고 명령, 따로 저장 과정을 거치지 않아도 원본 데이터가 즉시 수정됨
오늘은 유독 집중이 잘 되지 않는 월요일이었다.
손을 많이 움직여야 잠이 덜 오는데, 하루 종일 코드카타를 제외하고는 강의 수강 위주로 진행하다 보니 체력적으로도 조금 힘들게 느껴졌다.
아직 전처리와 시각화 과정은 복사/붙여넣기 위주로만 따라 해봤고, 직접 코드를 작성해보지는 못해 감이 잘 잡히지 않는다.
그래도 튜터님 말씀처럼 비슷한 과정을 여러 번 반복하다 보면, 전처리와 시각화를 어떻게 접근해야 하는지 자연스럽게 익숙해질 거라고 생각한다.
이번 주에는 성취도 평가도 예정되어 있으니, 틈틈이 복습도 병행해야겠다.
'내일배움캠프 데이터 분석' 카테고리의 다른 글
| 21일차) 내일배움캠프 데이터 분석 TIL - 파이썬 전처리/시각화(4) (0) | 2026.01.21 |
|---|---|
| 20일차) 내일배움캠프 데이터 분석 TIL - 파이썬 전처리/시각화(3) (0) | 2026.01.20 |
| 260118) 주말 SQL/파이썬 코드카타 (2) | 2026.01.18 |
| 18일차) 내일배움캠프 데이터 분석 TIL - 파이썬 전처리/시각화(1) (0) | 2026.01.16 |
| 17일차) 내일배움캠프 데이터 분석 TIL - 파이썬 기초(9) (0) | 2026.01.15 |
- Total
- Today
- Yesterday
- 텍스트분석
- 머신러닝
- 코드카타
- 판다스
- SQL
- 통계
- 데이터분석입문
- github
- 코딩기초
- 프로그래밍입문
- 구글코랩
- 중학생코딩
- 데이터시각화
- 내일배움캠프
- git
- Python
- 코딩처음
- Til
- 파이썬
- 데이터분석
- 비전공자코딩
- 태블로
- GoogleColab
- 파이썬입문
- Tableau
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |